

Context Engineering(脈絡工程,又譯上下文工程)是一套系統化設計 AI Agent 輸入資訊的工程方法,目的是讓 Agent 在多步驟、長流程的任務中維持穩定。當企業的 AI Agent 上線後出現「越跑越笨、越用越貴」的狀況,問題往往不在模型本身,而在脈絡工程沒做好。本文從企業導入視角,拆解脈絡工程是什麼、為何 2026 年它取代提示工程成為落地核心,以及它如何決定一個 AI Agent 專案的成敗。

Context Engineering(脈絡工程,又譯上下文工程)是指系統化地設計、組裝與管理「AI Agent 在每一步決策前實際看到的資訊」的工程方法,涵蓋系統提示、歷史對話、檢索結果、工具輸出與任務狀態。它的目標不是把輸入寫得漂亮,而是確保 Agent 在多步驟任務中,每一步都拿到「剛好足夠、剛好正確」的資訊。
如果你的企業已經導入 AI Agent,可能遇過這樣的場景:上線第一週表現亮眼,到了第二個月,同事開始抱怨「它好像變笨了」——回答開始離題、忘記前面交代過的設定,API 帳單卻一路往上爬。多數人第一反應是「模型不夠強」或「該換一家供應商」。但實情往往相反:模型沒有變差,是它每一步「看到的東西」出了問題。
這正是 2026 年 AI 工程圈最重要的觀念轉變。當 AI 從「一問一答的聊天機器人」進化成「能自己拆解任務、呼叫工具、連續執行的 Agent」,決定成敗的關鍵不再是單一一句提示詞寫得好不好,而是整個資訊環境設計得對不對。脈絡工程,就是這套設計資訊環境的紀律。
對正在評估或已經導入 AI Agent 的企業來說,這個觀念之所以重要,是因為它直接對應到一個很現實的問題:為什麼有些 AI Agent 專案能穩定運作一年,有些卻在第六個月悄悄失控、最後被迫終止。答案常常不在技術選型,而在有沒有人把脈絡工程當一回事。

Prompt 工程不夠用,不是因為它做錯了什麼,而是因為 AI 的使用方式變了——它從「人類給一句話、AI 回一句話」的靜態問答,變成「AI 連續執行數十步、自己決定下一步」的動態流程。當輸入不再只是一句人寫的提示,提示工程能管的範圍就不夠了。
提示工程誕生於 2022 年底的聊天機器人時代。那時人與 AI 的互動是單回合的:使用者在對話開頭設好一段提示詞,就能有效讓回答貼近預期。在那個情境下,「把那句話寫好」幾乎等於「把 AI 用好」。
但進入 2026 年的 Agent 時代,互動模式徹底改變。一個生產級的 AI Agent 在完成一項任務時,可能要連續進行數十次甚至上百次的工具呼叫、檢索與推理。它每一步「看到的輸入」不再只來自人類的那句話,而是混合了系統提示、先前每一輪的對話、檢索回來的文件片段、工具回傳的結果,以及任務進行到一半的狀態。
Anthropic 與研究機構 Material 於 2025 年底調查逾 500 位技術決策者的最新報告顯示 [2],已有 57% 的企業用 AI Agent 處理多步驟工作流程、其中 16% 更進展到橫跨多個部門的完整流程;2026 年將有 81% 計畫挑戰更複雜的應用場景。這正是脈絡工程需求急遽升高的根本原因——服務的流程越長、越跨部門,每一步要管理的資訊環境就越複雜。
這代表一件事:輸入變成一個動態、會隨任務推進不斷膨脹的系統,而不是一段寫死的文字。提示工程處理的是「人說了什麼」,但 Agent 的麻煩有八成出在「人沒說、卻被塞進去的那一大堆東西」。管理那一大堆東西,需要的是另一套方法。
理解兩者差異最簡單的方式,是看它們各自管什麼。提示工程關注「你對 AI 說什麼」——指令怎麼下、格式怎麼排、要不要給範例。脈絡工程關注「AI 在那一刻還看到了其他什麼」——記憶、檢索結果、工具輸出、任務狀態、控制流程,全都算。
換句話說,提示工程是脈絡工程的一部分,但脈絡工程的範圍大得多。AI 領域研究者 Andrej Karpathy 把脈絡工程描述為一門「在脈絡視窗中填入剛好正確資訊」的精細學問——重點落在「剛好」:太多會稀釋注意力、推高成本,太少會漏掉關鍵限制。
下面這張表整理兩者的核心分工:
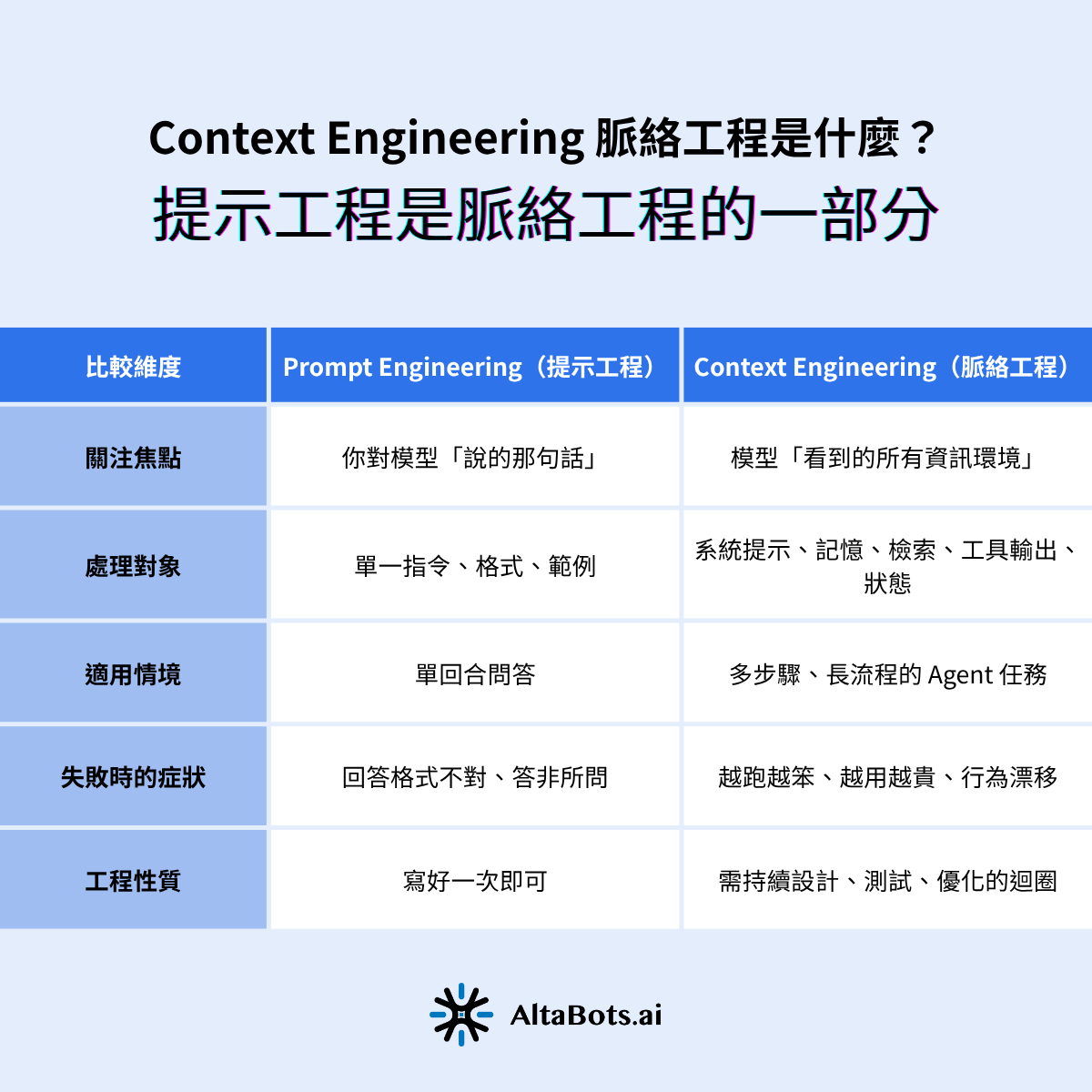
此表比較提示工程與脈絡工程的核心分工。第一,關注焦點不同,提示工程管你對模型說的那句話,脈絡工程管模型看到的整體資訊環境。第二,處理對象不同,前者是單一指令與格式,後者涵蓋系統提示、記憶、檢索與狀態。第三,提示工程適用單回合問答,脈絡工程適用多步驟長流程任務,失敗症狀也從答非所問變成越跑越笨。
值得釐清的是,這不是「提示工程被淘汰」,而是「重心上移」。一句提示詞依然要寫好,但當 AI Agent 要穩定運作,真正該投入心力的是把整個資訊環境設計對。這也是為什麼 2026 年工程圈的共識,已經從「找到神奇咒語」轉向「建立一套管理輸入的系統」。

AI Agent 上線後表現滑落,幾乎都能歸到三類脈絡問題:注意力被稀釋、成本失控、錯誤無法歸因。這三者背後是同一個根因——沒有人在管理 Agent 每一步實際看到的資訊。以下是這三個現場的真實樣貌。
第一個現場,是 Agent「跑著跑著就忘了自己是誰」。一個對話型 Agent 在前三輪表現得很到位,到第十輪、第十五輪,當初設定好的人設與角色開始鬆動:原本嚴謹的角色變得隨和、原本扮演提問方的角色開始反過來回答問題。
這不是模型壞掉,而是大型語言模型的注意力會被後續對話的內容逐步拉走。對話越長,最開頭那段角色定義在模型「眼中」的份量就越淡。Data-DI 在實際的對話型 Agent 落地專案中也反覆遇到這個現象 [5],最後的解法不是把人設寫得更長,而是設計一個機制,讓模型在每一輪回應前都重新「複習」一次自己是誰——這就是脈絡工程在實務上的樣子:不是寫死一段文字,而是動態地管理它。
第二個現場藏在帳單裡。Agent 每進行一步推理或工具呼叫,系統往往會把同一套系統提示、政策說明、工具描述、完整歷史對話原封不動再送一次給模型。一個任務跑數十步,這些重複資訊就被計費數十次。
Datadog《2026 State of AI Engineering》報告分析數千個企業生產環境的 LLM 呼叫記錄後發現 [3],高達 69% 的輸入 token 花在系統提示(政策指令、工具定義、格式規則等)上,使用者實際輸入僅占其中一小部分;即使是支援快取的模型,也只有 28% 的呼叫真正用上快取讀取,代表多數呼叫仍在重複處理同一份完整提示。換句話說,很多企業的 AI 帳單,有一大塊是付給了「沒有被管理的重複資訊」。脈絡工程要解的,正是讓每一步只帶該帶的東西。
第三個現場最隱蔽,也最致命。當 Agent 答錯了,團隊卻說不清楚是哪裡出問題:是檢索回來的文件不對?是歷史對話把它帶偏?還是工具輸出的雜訊蓋過了真正的訊號?
當一個 Agent 的輸入是一鍋把所有東西混在一起的湯,出錯時就無從拆解。而當脈絡被妥善分層——靜態的系統提示、動態的檢索結果、暫存的工具輸出各自分明——團隊才能快速定位「是哪一層的資訊汙染了決策」。脈絡的結構,決定了一個團隊「修得動還是修不動」自己的 AI Agent。這也讓問題從「換個更強的模型」轉向「把資訊環境整理乾淨」——後者,才是多數企業真正缺的能力。
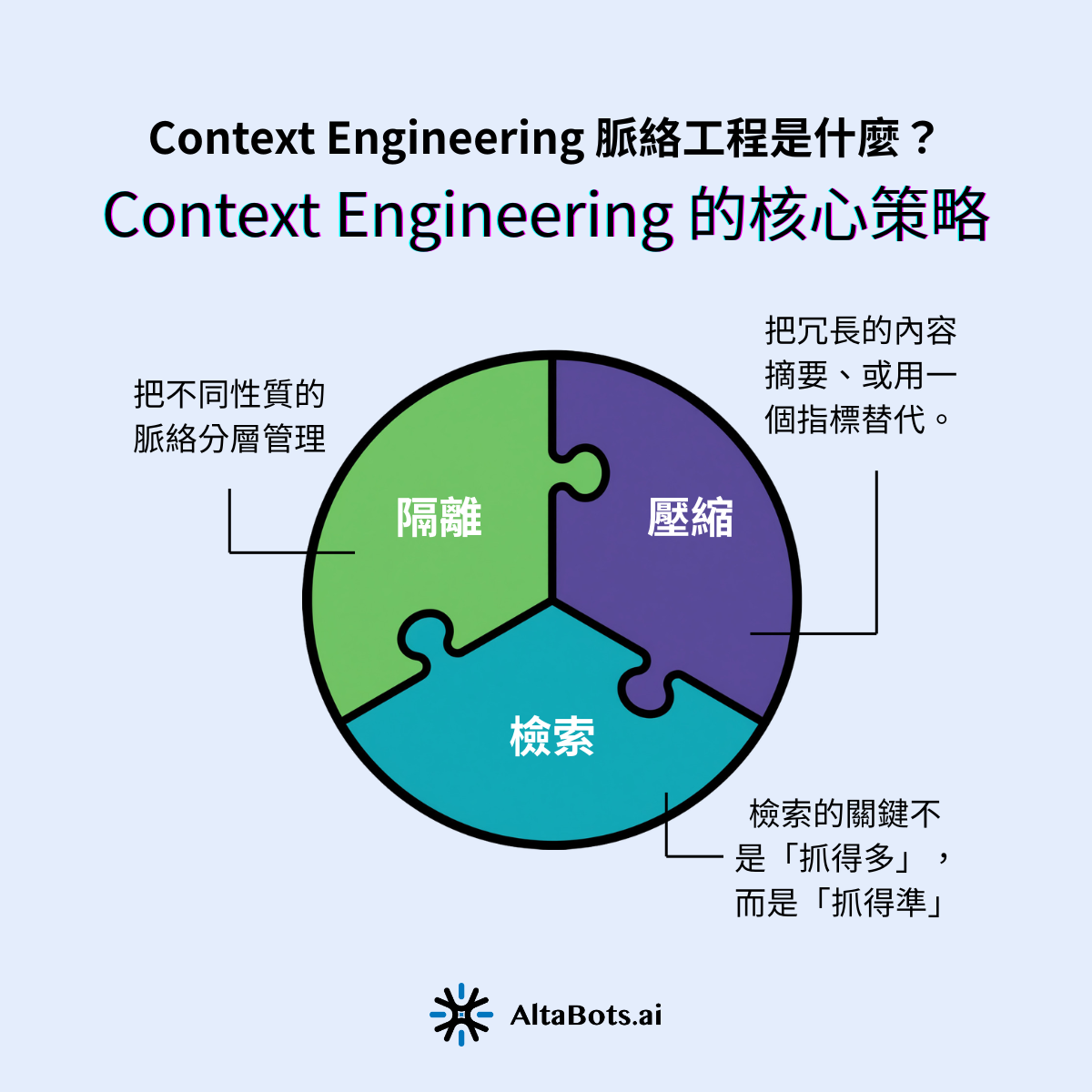
脈絡工程的核心,可以濃縮成一句話:在 Agent 的每一步,只放進「剛好足夠、剛好正確」的資訊。要做到這件事,業界已經發展出一套相對成熟的工程紀律,背後的原則彼此相通。
不論用哪一家平台、哪一個模型,脈絡工程的實作大致圍繞三個基本動作。理解這三個動作,不需要工程背景,但能幫企業判斷一個供應商到底有沒有在做這件事。
第一是壓縮。當歷史對話與工具輸出越積越多,與其原封不動全部送進模型,不如把冗長的內容摘要、或用一個指標替代。例如一段幾千字的工具回傳結果,可以濃縮成關鍵幾行,或標記成「詳見某筆紀錄」。壓縮做得好,能同時解決成本與注意力兩個問題;但壓縮也有風險——粗糙的摘要可能把「刪除前必須先詢問」這類關鍵限制濾掉,所以壓縮什麼、保留什麼,本身就是需要設計的。
第二是檢索。Agent 不需要、也不應該把所有知識都背在脈絡裡,而是在需要時才去知識庫把相關片段抓進來。這就是檢索增強生成(RAG)扮演的角色。檢索的關鍵不是「抓得多」,而是「抓得準」——抓回一堆勉強相關的文件,反而會用雜訊淹沒真正有用的訊號。Data-DI 在多篇文章中拆解過知識庫的建置與檢索品質,這部分可延伸閱讀我們整理的RAG 與重排技術。
第三是隔離。把不同性質的脈絡分層管理——靜態的系統提示、動態的檢索結果、暫存的工具輸出各自分明,而不是混成一鍋。隔離做得好,不只讓 Agent 的決策更乾淨,也讓出錯時能快速定位是哪一層出了問題。對需要多個 Agent 協作的複雜場景,隔離更進一步體現在架構設計上,這部分可參考Multi-Agent 多代理協作揭秘。
關於這套紀律,企業最需要建立的一個認知是:脈絡工程不是「設定一次就好」的工作,而是一條持續運轉的迴圈。
短期看,每次模型推理前,要即時篩選出當下必要的脈絡;長期看,隨著任務型態演變、底層模型版本更新、知識庫內容擴充,整套脈絡策略都要跟著調整。一個今天設計得很好的脈絡架構,半年後可能就需要重整。這也是為什麼脈絡工程被視為一門「工程」——它需要設計、實作、測試、優化的完整循環,而不是寫完一份提示詞就收工。
對企業來說,這個「迴圈」特性帶出一個關鍵的現實問題:這套要持續運轉的工程紀律,公司內部有沒有人能扛?這正是下一段要談的——脈絡工程從一個技術名詞,變成一個導入決策。
如果你讀到這裡的身分不是工程師,而是要為公司做 AI 導入決策的人,那麼脈絡工程對你最重要的意義只有一句話:它決定了你那筆 AI Agent 預算,半年後是變成資產,還是變成一個沒人敢碰的爛攤子。
前面提到的那些症狀——越跑越笨、帳單失控、出錯沒人說得清原因——攤開在管理層面前,不會被叫做「脈絡工程問題」,而會被叫做「這個 AI 專案不太行」。多數失敗的 AI Agent 專案,技術病根其實高度集中,而脈絡管理就是其中最常見的一個。
這也解釋了一個常被引用的產業預測:研究機構 Gartner 估計 [1],到 2027 年底,將有超過四成的代理式 AI 專案被企業中止,主因包括成本失控與商業價值不明。Capgemini 研究院針對 1,500 位跨產業高階主管的最新調查也印證同一個落差 [4]:目前僅 2% 的組織已規模化部署 AI Agent、12% 部分規模化,逾六成仍停留在試點或觀望階段,而低於兩成的組織認為自己的資料與技術基礎建設已成熟到足以支撐規模化部署。值得注意的是,「成本失控」與「基礎建設不成熟」幾乎都直接對應前面講的重複 context 問題與脈絡管理缺口。也就是說,那四成裡有相當比例,不是輸在「AI 不夠強」,而是輸在「沒有人把資訊環境管好」。對決策者而言,這個區別至關重要——前者要你換技術,後者要你換做法。
理解脈絡工程之後,企業評估 AI Agent 供應商時,該問的問題會明顯不同。
過去企業比較供應商,問的多半是功能題:能不能客製化、支不支援某個通路、介面好不好操作。但這些功能題,每一家供應商都會給你漂亮的答案。脈絡工程的觀念,讓你能問出真正有鑑別度的方法題:

此表對照企業評估 AI Agent 供應商時,過去常問的功能題與真正該問的方法題。功能題如能否客製化、是否 No Code、上線多久、有無案例。方法題則改問對話變長如何防遺忘、如何控制每步的 context、模型升級如何確保不退步、答錯時如何定位脈絡層級。方法題更能鑑別供應商真實交付能力。
會做的供應商,能就右邊這些問題給出具體、有結構的答案;只會賣工具的供應商,會用「我們技術很成熟」這類形容詞帶過。關於如何系統性地判斷一個 AI Agent 供應商是否真有交付能力,可延伸閱讀AI Agent 顧問怎麼選:5 個交付實務檢核點,那篇文章把簽約前的壓力測試問題整理成一張可帶進會議室的表。
說到底,脈絡工程對企業決策者的價值,不是讓你變成半個工程師,而是給你一把尺——讓你在預算下去之前,就分得出誰能把 AI Agent 帶到「穩定運作」,誰只是把它「做出來」而已。
如果你是想解決 Codex、Claude Code 的 context 管理問題,前面原則同樣適用,差別只在規模。企業要撐的是多部門的 AI Agent,問題會放大成組織負擔。想知道團隊準備度,可花 3 分鐘做這份AI Agent 導入準備度測驗。
AltaBots.ai 是 Data-DI 推出的企業級 AI Agent 平台,它的核心差異化不是「No Code 工具」本身,而是「從決策到上線,顧問全程陪跑」——而脈絡工程,正是這套陪跑機制裡最需要顧問經驗的一環。
前面談過,脈絡工程是一條需要持續運轉的迴圈:壓縮什麼、檢索多準、怎麼分層隔離、模型升級後怎麼重整。這些都不是「介面上拉一拉」就能解決的問題,而是需要有人根據企業的實際業務場景做判斷。
這就是為什麼一套單純的 No Code 平台,沒辦法真正解決脈絡工程。No Code 解決的是「誰來建」的問題——讓不會寫程式的人也能組出一個 Agent;但它沒解決「該怎麼建」的問題——壓縮策略怎麼設、知識庫怎麼拆分、人設漂移怎麼防。你有了工具,仍然會卡在不知道脈絡該怎麼管。AltaBots.ai 之所以不把 No Code 當成定位主軸,原因就在這裡:對企業客戶來說,真正的價值不是「我能自己拉」,而是「半年後它還能穩定產生價值」。
在 AltaBots.ai 的雙軌交付模式裡,脈絡工程不是一個拋給客戶自行摸索的功能,而是被拆進顧問陪跑的每一個階段:
需求訪談階段,顧問會先釐清這個 Agent 上線後要處理哪些任務、脈絡會從哪些來源進來,據此規劃資訊環境的架構,而不是急著寫提示詞。開發階段,針對前面提過的人設漂移、角色錯亂等真實踩坑,顧問會設計對應的脈絡注入機制,例如讓模型每一輪重新複習自己的角色定義。上線後的 Evals 陪跑階段,顧問會持續監控 Agent 的表現、定位錯誤是出在哪一層脈絡,並隨著模型版本更新調整整套策略——也就是讓那條「脈絡工程的迴圈」真的有人在轉。
換句話說,AltaBots.ai 把脈絡工程從一個抽象的技術名詞,變成一套有人負責、有方法、可被驗收的交付流程。對第一次導入 AI Agent、或前一次導入失敗想重來的企業來說,這正是「找工具」和「找夥伴」之間的差別。
回到開頭那個場景:AI Agent 上線第二個月,同事抱怨它變笨了、帳單卻越來越高。讀完這篇文章,你應該已經知道——這多半不是模型的錯,而是脈絡工程沒人在管。
2026 年,AI 從聊天機器人進化成能自己執行任務的 Agent,決定成敗的關鍵也跟著從「寫好一句提示詞」上移到「設計好整個資訊環境」。脈絡工程不是一個讓你變成工程師的技術名詞,而是一把尺:它讓你在預算下去之前,就分得清楚一個 AI Agent 專案會穩定運作一年,還是會在第六個月悄悄失控。對企業決策者來說,看懂這把尺,比看懂任何一份功能規格都重要。
如果你的公司正在評估導入 AI Agent,或前一次導入卡在「越跑越不穩」的狀況想重來,立即預約一場免費的 AI Agent 導入評估諮詢——Data-DI 的顧問會根據你公司目前的階段、團隊配置與業務場景,和你一起釐清脈絡工程這條迴圈該怎麼轉、由誰來轉,幫你判斷現階段最務實的下一步。
[1] Gartner.(2025). Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027. Gartner Newsroom.
https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
[2] Anthropic × Material.(2025). The 2026 State of AI Agents Report. Claude by Anthropic.
https://claude.com/blog/how-enterprises-are-building-ai-agents-in-2026
[3] Datadog.(2026). State of AI Engineering 2026. Datadog.
https://www.datadoghq.com/state-of-ai-engineering/
[4] Capgemini Research Institute.(2025). Rise of Agentic AI: How Trust Is the Key to Human-AI Collaboration.
https://www.capgemini.com/insights/research-library/ai-agents/
[5] Data-DI(2026)。AltaBots.ai 內部專案紀錄。本文中對話型 Agent 的人設漂移、角色錯亂等實務踩坑與對應解法,來自 Data-DI 在多個 AI Agent 落地專案中的實戰經驗整理,已去識別化處理。
