

本段重點:先看見問題在哪,才知道資源該砸哪裡
Gartner 2025 年預測,超過 40% 的 Agentic AI 專案會在 2027 年前被取消,主因是成本失控、商業價值不明、風險管控不足 [1]。但失敗的真正原因,不是模型不夠強,而是團隊沒有一套系統化的方法找出問題在哪裡。錯誤分析(Error Analysis)就是這套方法——它幫你從一堆出錯的對話日誌中,歸納出可量化的失敗模式,讓優化資源花在刀口上,而不是每天打地鼠式修 Bug。
如果你正在評估企業導入 AI Agent,這篇文章會給你一套可重複、可量化的 SOP,協助團隊從「無限修 Bug」的循環中跳出來。


本段重點:Agent 不是傳統軟體,靠手動測試只會越改越糟
傳統 Debugging 強調重現問題、逐步定位,像找漏水點;但 LLM Agent 的輸出帶有隨機性,同樣的輸入可能產出不同結果,傳統單元測試無法全面覆蓋。錯誤分析則像用熱顯像儀看全局——不糾結於單一錯誤,而是透過分類與統計(多少比例是工具調用錯誤?多少是意圖理解失敗?),找出最值得投入資源的優化點。
Anthropic 在 2026 年初發布的工程指南〈Demystifying Evals for AI Agents〉直接點出這個痛點:當使用者反饋「改版後變差」,沒有評估機制的團隊只能靠猜測與反覆檢查,陷入「等使用者抱怨 → 嘗試手動重現 → 修一個 Bug → 祈禱沒引入新問題」的被動循環 [2]。結果是:你無法區分「真回歸」與「隨機噪聲」,也無法量化「這次到底有沒有變好」。
Andrew Ng 用「貓狗辨識」案例說明錯誤分析的力量:他檢查錯誤圖片並分類,發現 50% 是狗被誤判成貓、30% 是大型貓科誤判、20% 是圖片模糊 [3]。透過錯誤分類,團隊明確知道優化重點在哪,而不是盲目擴充資料量。同樣的邏輯套用到 Agent:你需要先看到失敗模式的分布,才能決定下一步該修 Prompt、補知識庫、還是換工具設計。

本段重點:80% Agent 出包,根因藏在 Context 裡
在進入 6 步驟流程前,先建立一個關鍵認知:多數 Agent 上線後的詭異行為,不是模型問題,而是 Context(上下文)失控。AI 研究者 Drew Breunig 在 2025 年提出「Context 四種失敗模式」框架,已被 Anthropic 等業界引用為 Agent 除錯的基礎心智圖 [4]:

下次你的 Agent 做出無法解釋的行為時,先把這四種模式逐一比對,幾乎能定位其中一種。錯誤分析的人工標註步驟(後面 Step 2 會詳述),正是要把對話日誌依這類失敗模式分類——而不是用模糊的「回覆不準」描述。
本段重點:先做錯誤分析,再做 Evals——順序錯了等於白做
錯誤分析跟 Evals 是兩件事,但常被混為一談。錯誤分析在前、Evals 在後:先用人工標註找出系統性失敗模式(負面表列),再針對「每一種失敗模式」設計對應的 Evals 測試案例。如果沒有錯誤分析就直接寫 Evals,測試案例容易流於形式,無法真正找出系統的核心問題 [5]。
而 Evals 內部又分兩種,差別在於評估對象:

簡單記憶:AI Evals 是「零件檢查」,Agent Evals 是「整車路測」。Data-DI 顧問團隊在輔導客戶時觀察到,台灣多數企業卡在「直接跳去寫 Evals 卻沒先做錯誤分析」的階段——結果寫了一堆通過的測試,使用者投訴卻沒減少。正確順序是:日誌收集 → 錯誤分析 → 失敗模式分類 → 對症設計 Evals。

本段重點:20–50 筆失敗案例就能起步,別等到完美再開始
很多團隊延遲建立錯誤分析機制,理由是「以為要有幾百個樣本才有意義」。Anthropic 在〈Demystifying Evals for AI Agents〉中直接打破這個迷思:「從真實失敗中抽出 20–50 個簡單任務,就是很好的起點」[2]。原因是在 Agent 開發早期,每次系統改動都帶來明顯可見的影響,效應夠大,小樣本就足以判斷方向。
對應到台灣企業實務,業界整理的做法是分階段累積樣本量:
挑樣本就像抽血檢查——要有代表性,不是越多越好。起步階段最該避免的,是堅持「等樣本量夠了再開始」,結果一拖半年什麼都沒做。
本段重點:六步驟一條龍,每步驟都有產出與檢核點
完整的 Agent 錯誤分析流程包含 6 個步驟,每個步驟都有明確的輸入、輸出與下一步銜接:
每一步都需確保樣本具代表性、錯誤分類具體可操作,並能以明確品質指標追蹤成效。下面分階段拆解。

本段重點:日誌篩得準、標註標得具體,後面才有東西可分類
錯誤分析的起點是收集對話日誌,但通用型 LLM 缺乏多維度篩選功能——你只能看到一整串對話,難以快速定位哪幾筆是異常。如果你使用具備觀測性(Observability)的 AI Agent 平台,例如 AltaBots.ai 內建的日誌功能,可以從使用者意圖、工具調用、回覆延遲等多個維度交叉篩選,大幅縮短找出異常對話的時間。Data-DI 顧問團隊在輔導客戶導入時,會協助設計符合各業務場景的日誌標籤架構,讓後續錯誤分析能直接套用。
挑出代表性樣本後,進入人工標註階段。標註時請聚焦「第一個失敗點」——也就是對話中最早出錯的位置,而不是把整段不滿意都標起來。避免用「回覆不準」「答得不好」這類模糊詞;改用具體描述,例如:
標註時順手寫下可執行的修正建議(例:補退貨流程關鍵字進意圖分類訓練集),讓後續步驟能直接執行。建議標註 20–50 筆代表性樣本作為起步,涵蓋各種常見場景。
、

本段重點:分類錯誤像整理衣櫃,先處理最多的問題
人工標註完 20–50 筆樣本後,把這些標註結果交給 LLM,請它歸納出系統性失敗模式並依頻率排序。例如:「45% 屬於意圖理解失敗、30% 屬於工具調用錯誤、25% 屬於格式不符」。這一步用 LLM 而非人工,是因為當樣本量擴充到上百筆時,人工分類耗時且容易陷入主觀偏誤。
接著對每一類失敗模式做「Fix or Evals」決策:
這個分流的關鍵原則是:不要把所有問題都丟給 Evals。能直接修的問題立刻處理,省下的時間應該投入到那些「需要長期監控的主觀品質」。許多團隊一開始就想做全自動評估,結果 Evals 太龐大反而沒人維護。

本段重點:用二元判定取代分數制,省時間又少爭議
Agent Evals 業界常用兩種方法:
讓另一個 LLM 對 Agent 輸出進行打分。關鍵設計原則:採用二元判定(TRUE/FALSE)而非 1–5 分制。理由是分數制定義模糊(3.2 分跟 3.7 分差在哪?),二元判定則邊界清楚、利於自動化、爭議少。Anthropic 在實務經驗中也提到,二元判定能讓人類標註者與 LLM Judge 的一致性快速達到 90% 以上 [2]。
LLM Judge 上線後必須定期人工抽樣審核——通常每月抽 30–50 筆,計算「人類與 LLM Judge 不一致矩陣(misalignment matrix)」,持續優化 Judge 的 Prompt。
有明確標準答案的任務(例如 SQL 查詢、RAG 檢索結果),直接用黃金資料集比對。優點是高精度、可自動化;缺點是需要人力維護資料集,難以涵蓋開放式問答。
💡 實務建議:兩種方法組合使用——用 Golden Dataset 驗證關鍵路徑(不能錯的)、用 LLM Judge 監控全局品質(主觀層面)。建議多階段 Agent 系統可參考 Multi-Agent 揭秘 一文中的層級設計,再決定各層的 Evals 策略。
接著進入 CI/CD(持續整合與持續部署)整合:把 Evals 流程接到開發部署管線,每次模型或 Prompt 更新後自動跑回歸測試,確保舊問題不會復發。這就是業界近期討論度極高的 EDD(Evals-Driven Development,評估驅動開發)——對應傳統軟體的 TDD(測試驅動開發):先寫好評估指標,再去調整產品(更換模型、Prompt、工具),用評估結果決定是否上線。
Anthropic 把這個觀念形容為「瑞士起司模型(Swiss Cheese Model)」:沒有單一評估層能擋住所有問題,必須多層防護(自動 Evals + 生產環境監控 + A/B 測試 + 使用者回饋)疊加,才能涵蓋盲區 [2]。
一張表看懂兩種評估方式的差異。
下表整理 AI Evals 與 Agent Evals 的核心差異,供讀者快速比較:

兩種方法各有優缺點,靈活搭配效果最好。
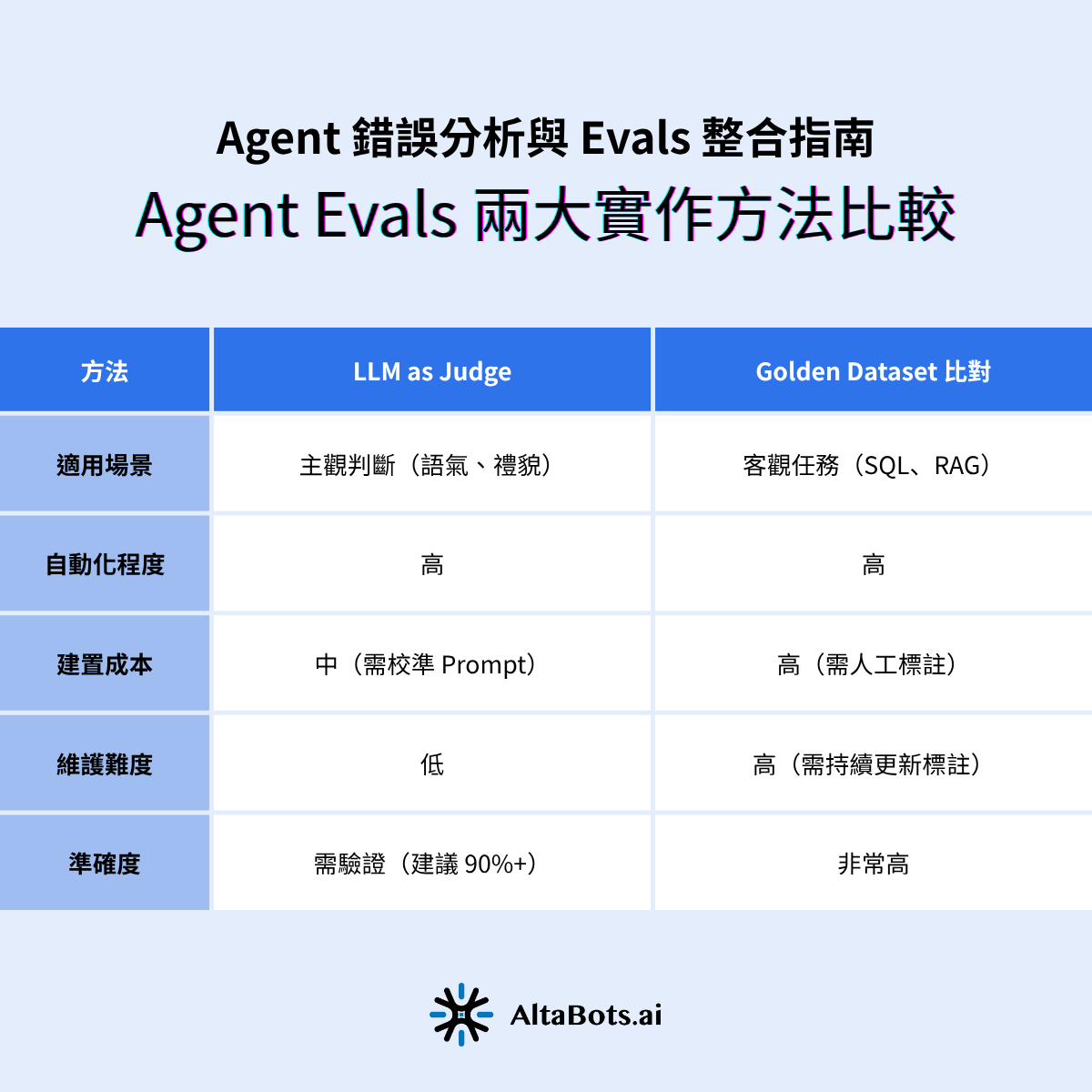
💡 建議:兩種方法可組合使用——用 Golden Dataset 驗證關鍵路徑,用 LLM Judge 監控全局品質。
本段重點:三個一踩就掉的坑,先看一下省半年走錯路
許多人以為有 LLM 就能全自動評估。AI 缺乏產品上下文與專業知識——例如它不知道你的系統裡根本沒「虛擬看房」這個功能,因此無法判斷某個輸出是否合理。初期階段仍需人類專家(Benevolent Dictator,具備領域專業的產品經理)參與,確保標註品質。
分數等級制會造成指標混亂且難以追蹤——3.2 分跟 3.7 分的差異難以解釋。LLM Judge 應僅針對單一失敗模式,採用二元(TRUE/FALSE)結果,提升一致性與自動化效率。
只看「總體一致性 90%」會忽略長尾錯誤——也許那 10% 不一致的,正好是高風險場景。建議分析不一致矩陣(misalignment matrix),檢查人類與 LLM Judge 的所有交叉情境,並持續優化 Judge 的 Prompt。
本段重點:流程跑得動,比流程設計得完美更重要
了解了 6 步驟流程後,許多團隊還是會在實務導入時卡關。以下是 Data-DI 顧問團隊在輔導台灣企業時,最常遇到的三個落地關鍵:
錯誤分析不只是修 Bug 的工具,而是驅動 LLM Agent 系統持續成長的核心引擎。許多客戶在我們協助下從「每天打地鼠」的被動模式,轉成有結構、可衡量的優化流程後,Agent 上線後的客訴率明顯下降,內部對 AI 的信任度也跟著提升。如果你想了解這套方法如何套用到你自家的 Agent 系統,例如 AI Agent 在企業實務的具體應用案例,可以參考我們的客戶案例集——或繼續往下看,我們提供針對你情境的免費診斷。
本段重點:30 分鐘聊清楚現況,再決定要不要做
每家企業的 Agent 系統狀態都不一樣——有的卡在意圖理解、有的卡在工具調用、有的還在評估要不要導入。如果你想釐清自己的系統實際卡在哪裡,Data-DI 提供 30 分鐘免費 AI Agent 診斷,由顧問檢視你目前的 Agent 設計、日誌結構、可優化的快速勝利點,並針對你的實際情境提出建議。
不需要先準備資料,把目前使用的工具與情境告訴我們即可。Data-DI 的定位不是賣工具,而是從策略到部署陪你走完——這也是 60% 以上客戶選擇我們的原因。立即 預約免費 AI Agent 診斷,30 分鐘釐清下一步該怎麼走。
[1] Gartner.(2025)。Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027. Gartner Newsroom.
https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027
[2] Anthropic.(2026)。Demystifying evals for AI agents. Anthropic Engineering Blog.
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
[3] Ng, A.(2018)。Machine Learning Yearning (Draft Version 0.5). deeplearning.ai.
http://bloglxm.oss-cn-beijing.aliyuncs.com/Machine_Learning_Yearning.pdf
[4] Breunig, D.(2025)。How Long Contexts Fail. dbreunig.com.
https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
[5] iHower.(2025)。什麼是 AI 應用評估的錯誤分析 Error Analysis? ihower blog.
https://ihower.tw/blog/12960-ai-evals-and-error-analysis
